vidivici.world
Junior Member level 3
Hi, all.
I implemented a 64-bit multiplier using Altera Quartus MegaWizard Plug-In Manager. The device is cyclone III series. But the classical timing analysis shows that it cannot even meet when tpd=20ns. I wonder why it can be so slow when the device is made with 65nm process, is there something wrong? Pls someone tell me, thank you!
The screenshots is below.
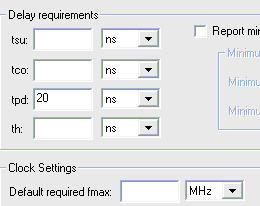

I implemented a 64-bit multiplier using Altera Quartus MegaWizard Plug-In Manager. The device is cyclone III series. But the classical timing analysis shows that it cannot even meet when tpd=20ns. I wonder why it can be so slow when the device is made with 65nm process, is there something wrong? Pls someone tell me, thank you!
The screenshots is below.

") . Now I get it, pipeline would be a hopeful solution~~
. Now I get it, pipeline would be a hopeful solution~~